
Disposition : À quels glyphes ou caractères sont affectés chacune des touches.
Kéa, une alternative extraordinaire au Qwerty
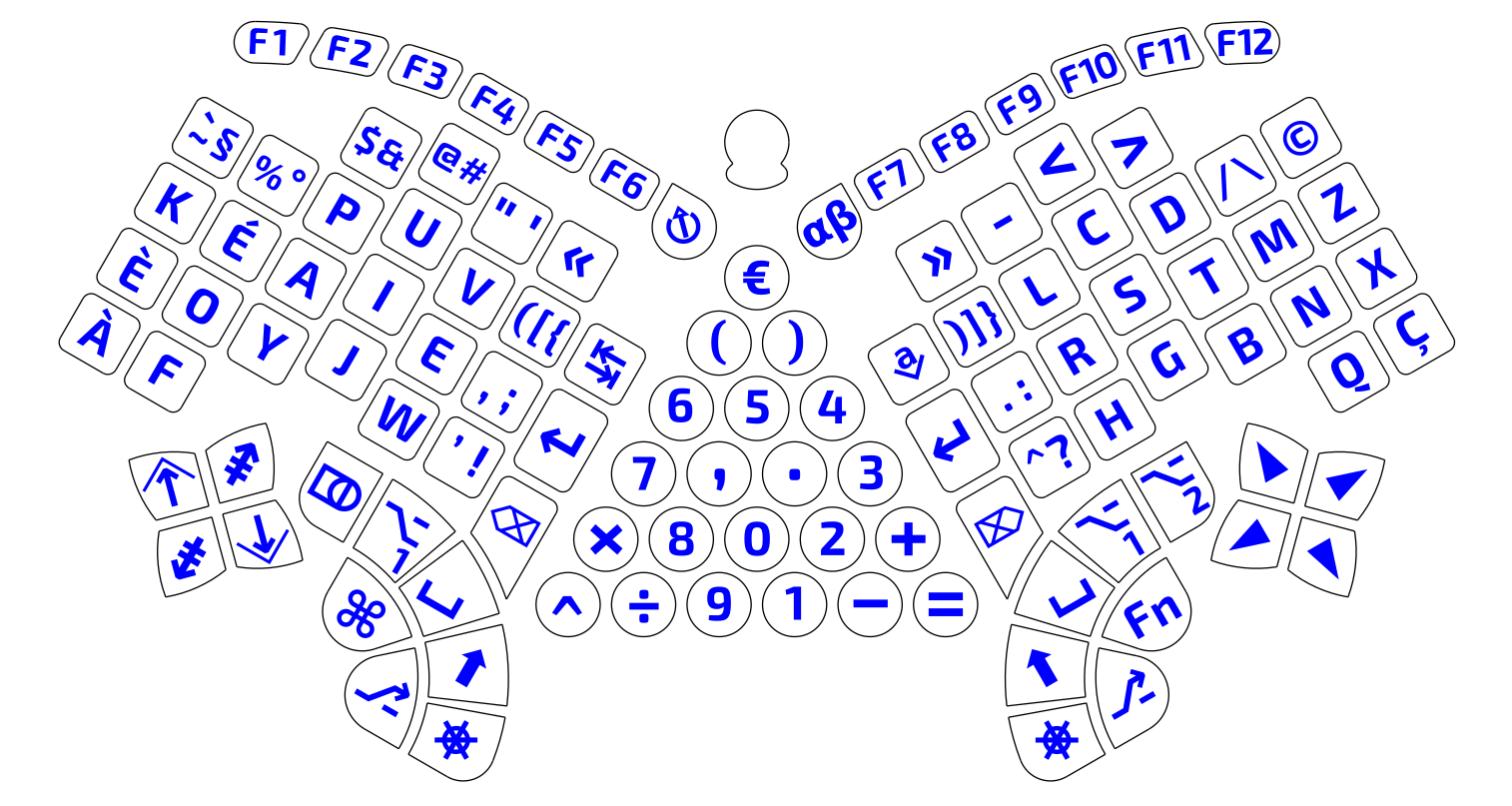
Kéa est basé sur la méthode Dvorak et inspiré du Bépo.
Pour obtenir une solution qui soit réellement ergonomique, une bonne géométrie ne suffit pas, il faut aussi choisir une bonne disposition de touche. C’est précisément le rôle du Kéa.
À ce titre, le Bépo peut également être un bon choix. Le Kéa se distingue du Bépo par le fait d’être dès le départ conçu pour un clavier dont la géométrie est ergonomique. Alors que le Bépo à vocation à s’insérer dans l’écosystème normé existant avec les géométries standards existantes tels que ISO (européen), ANSI (américain) ou JIS (japonais).
Ainsi, en un sens le Kéa est un fork (projet dérivé du même code source initial) du Bépo pour d’une part s’adapter aux nouvelles possibilités de la géométrie ToucheLibre et d’autre part pour offrir des possibilités nouvelles avec des caractéristiques inédites.
Voir la suite.
Les paradigmes de la disposition Kéa
Les choix initiaux pour construire cette disposition sont :
- Optimiser à la fois pour le français, l’anglais et l’espagnol.
- Pouvoir écrire toutes les langues basé sur l’alphabet latin en ayant en accès tous les types d’accent imaginables.
- Faciliter la programmation en ayant tous les caractères ASCII en accès facile.
- Accéder aux symboles mathématiques et techniques courants.
- Accéder à l’alphabet grec par une touche (dite) morte. C’est fort utile en science.
- Limiter le mouvement latéral du petit doigt.
- Accéder à l’alphabet phonétique pour faciliter l’apprentissage des langues.
- Faciliter la mémorisation du clavier en plaçant l’une à côté de l’autre, les touches proches par la forme, par la phonétique ou par leur origine historique (autant que possible en tout cas).
- Enfin, le Kéa proposera une extension par proximité phonétique vers les autres alphabet que le latin : Grec, Cyrillique, Arabe, Hébreu, Bopomofo (alphabet phonétique pour le Chinois) et les Kanas japonais.
Comment a été conçue la disposition Kéa ?
Le point de départ
J’ai fait le choix du Bépo pour point de départ car :
- il est pensé pour le français
- sa communauté très active a généré une grosse quantité de trucs et astuces fort inspirantes.
Construction d’un corpus
Un corpus, dans le domaine des claviers, est une somme importante de textes que l’on estime être représentative de la langue et de la diversité des usages. En calculant l’occurrence de chacune des lettres, on en déduit le taux d’utilisation des lettres de l’alphabet pour une langue donnée. On parle aussi d’analyse fréquentielle. L’établissement de cette connaissance est essentielle pour la mise en application de la méthode Dvorak.
Pour la petite histoire, l’analyse fréquentielle a été à l’origine de la première technique de décodage des messages cryptés fondée sur les mathématiques. On doit cette trouvaille au savant arabe Al‑Kindi au IXe siècle.
Pour le Kéa, on a voulu optimiser la disposition à la fois pour l’anglais, le français et l’espagnol (castillan), car ce sont 3 langues basées sur l’alphabet latin. Et elles ont le statut de langues internationales (selon les critères de l’ONU). Une langue obtient le statut de langue internationale par les critères suivants : nombre de locuteurs, nombres de pays qui ont cette langue pour langue officielle, l’influence politique, l’influence économique, l’influence scientifique et technique et l’influence culturelle. Les 3 autres langues à avoir ce statut sont le russe, le chinois mandarin et l’arabe classique.
Ainsi, on est parti de 3 corpus existant pour ces 3 langues et on a fait une moyenne arithmétique. Ce qui nous a donné le taux d’utilisation suivant:
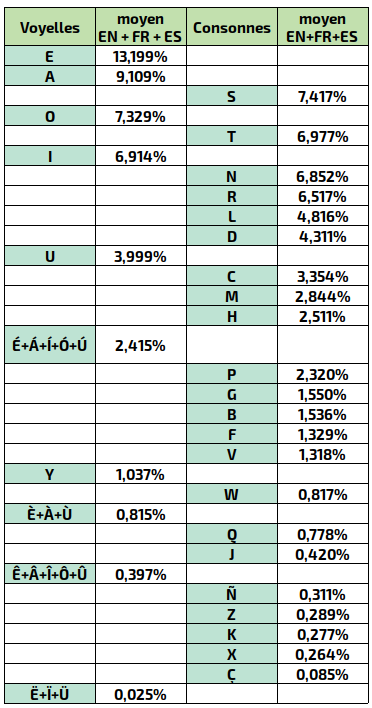
On en déduit donc immédiatement le pré‑positionnement suivant en se référant au taux d’accessibilité défini à la page «Géométrie» :

On obtient, et c’est une chance, un bon équilibre gauche / droite entre les voyelles les plus utilisées et les consonnes les plus utilisées.
Toutes les voyelles sont traditionnellement placées à gauche dans la méthode Dvorak. Mais l’inverse serait tout aussi viable. Séparer les voyelles et les consonnes permet de favoriser l’alternance main gauche / main droite dans l’exécution des digrammes (couple de lettre).
En suite, il faut rentrer dans le détail pour insérer toutes les lettres et équilibrer l’utilisation des deux mains et les doigts les uns par rapport aux autres. On procède par tâtonnement et itération. C’est a dire «à la main», on n’a pas développé d’algorithme compliqué comme pour le Bépo par exemple.
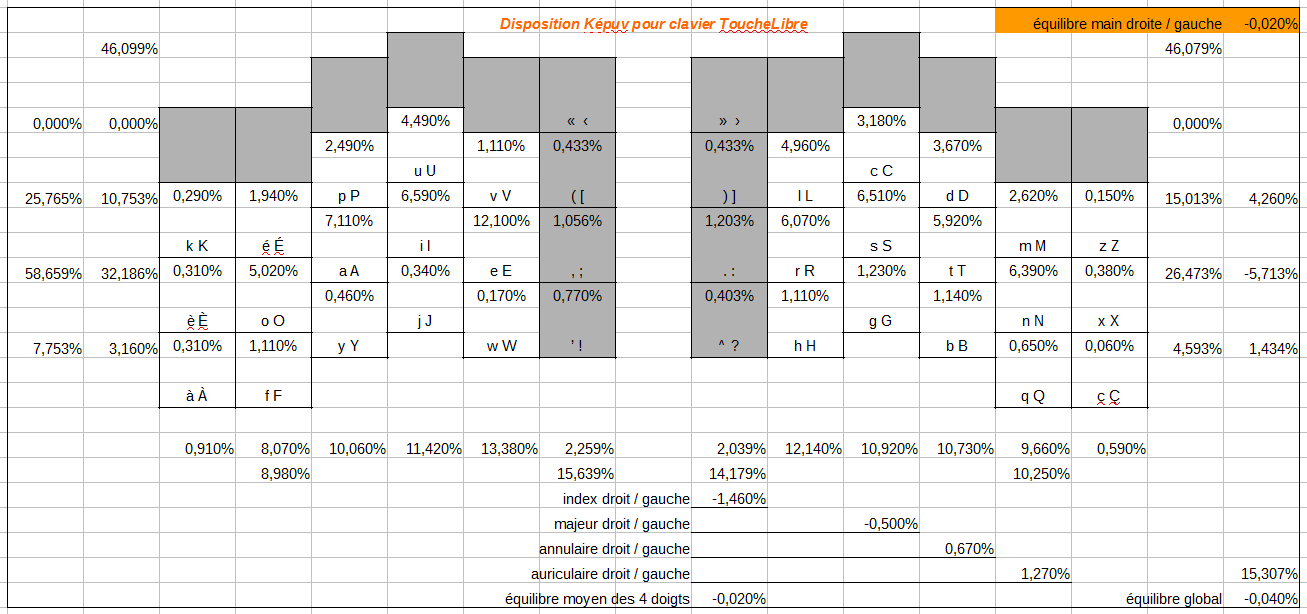
Ce qui donne les résultats suivants:
Pour le français :
Pour l’anglais :
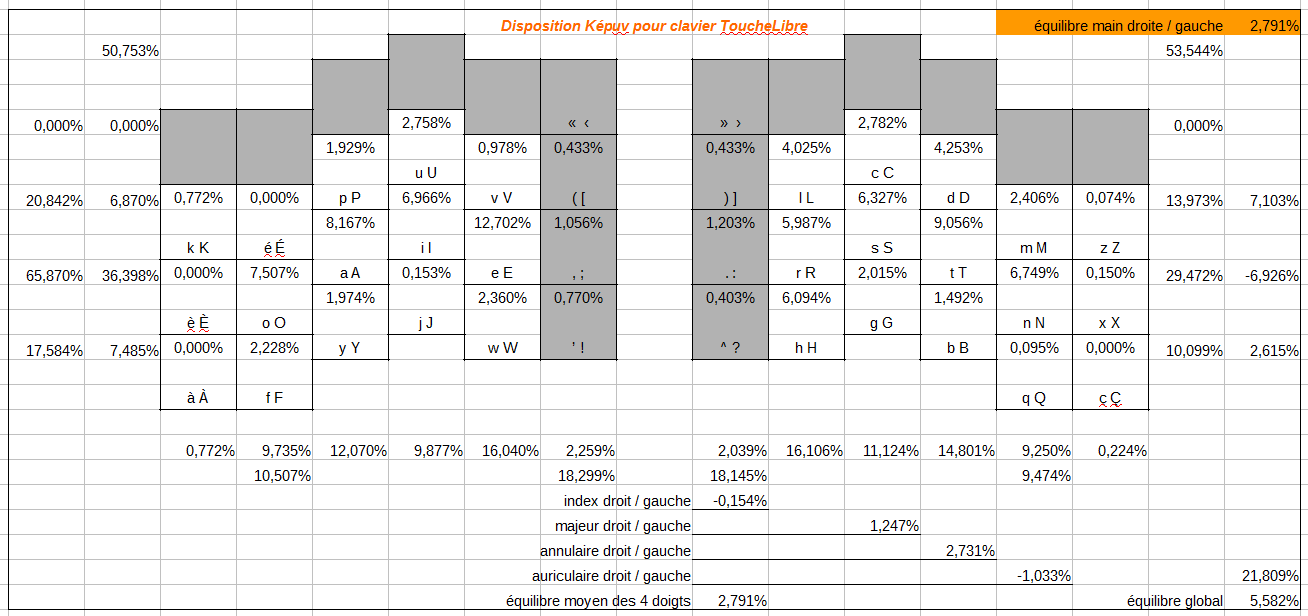
Pour l’espagnol :
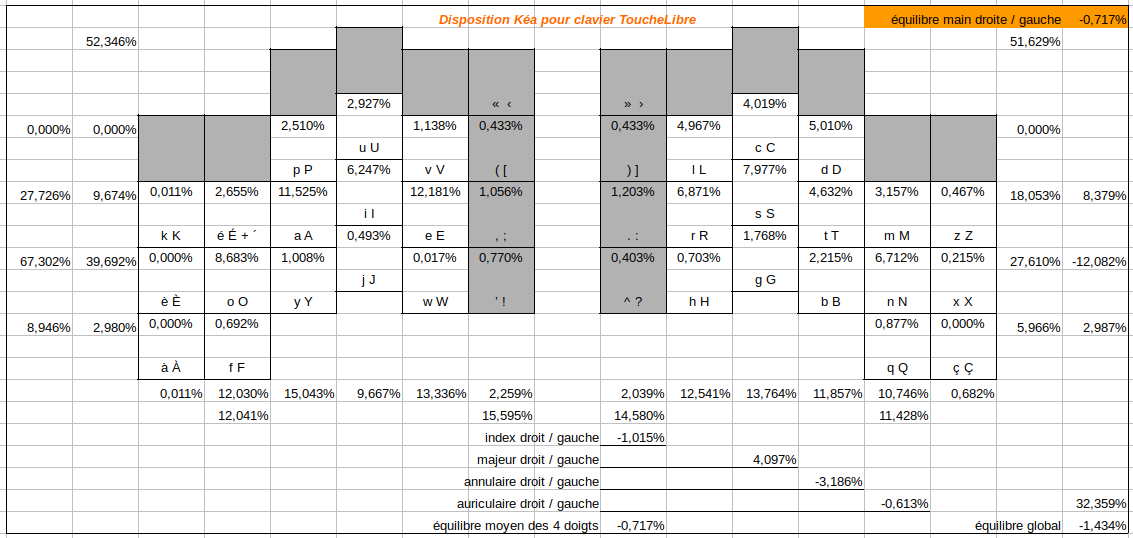
On peut ainsi comparer la performance ergonomique du Kéa par rapport au Qwerty ou Azerty (qui n’est jamais qu’une variante du qwerty).
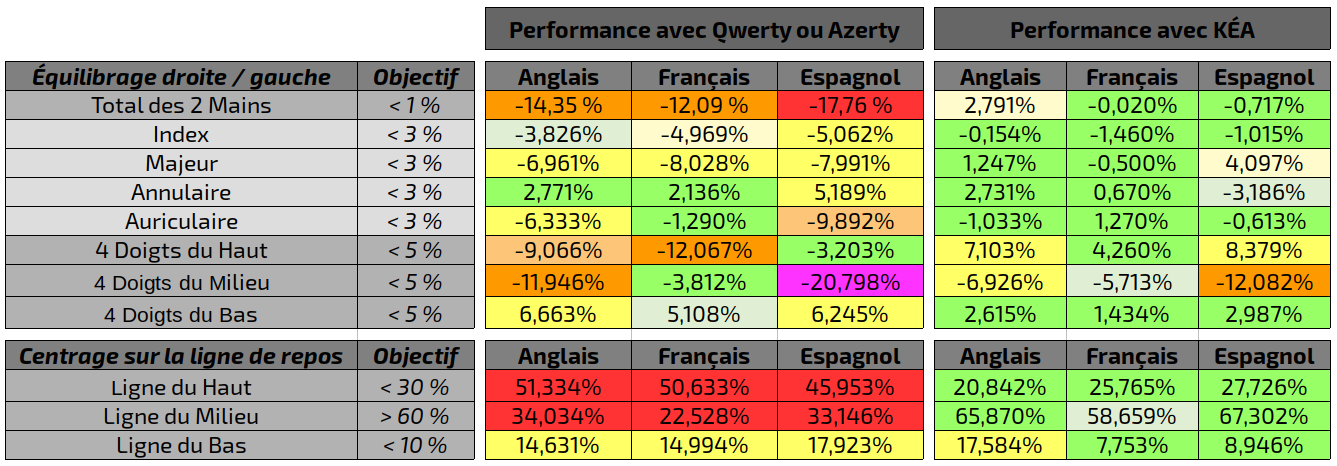
On constate qu’à tout point de vu le Kéa est nettement meilleur que le qwerty.
Par curiosité, on a regardé également ce que donne le Kéa pour 12 autres langues européennes.
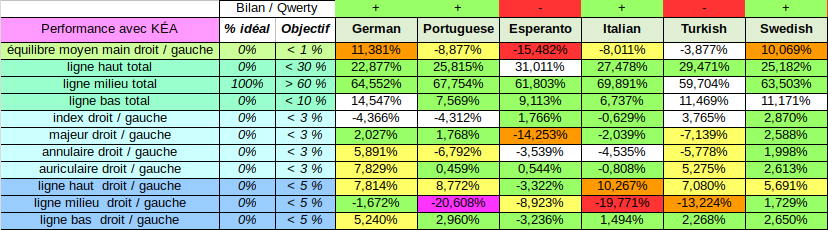
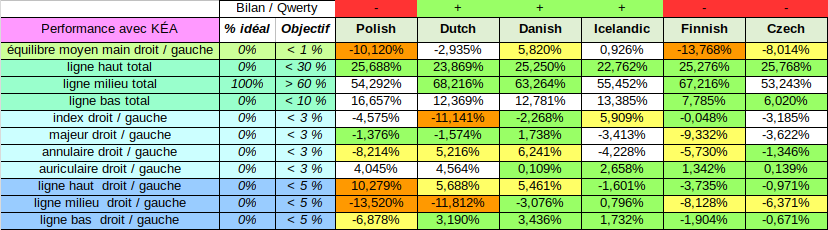
Et là surprise, le Kéa est également très bien adapté pour l’islandais (mieux que l’anglais!), bien adapté pour le hollandais et le turc. Pas si mal pour l’italien, le portugais, le danois et le tchèque. Pas terrible en revanche pour l’espéranto, l’allemand, le suédois, le polonais et le finnois.
Par rapport au qwerty, le Kéa améliore la situation pour l’allemand, le portugais, l’italien, le suédois, le hollandais, le danois, l’islandais. Dégradation en revanche pour l’espéranto, le polonais, le finnois et le tchèque.
Qu’on se le dise il est impossible d’obtenir une bonne optimisation pour toutes les langues à la fois. Il faut faire des choix. Toutefois le Kéa obtient une bonne performance en la matière pour les principales langues européennes. Ce qui enlève rien au fait que le Kéa permet d’écrire toutes les langues européennes car elle permet l’écriture de tous les signes diacritiques existants. Ce qui loin d’être le cas pour le qwerty, qui doit, lui, produire une grande quantité de variantes pour adresser toutes les langues à base latine.
Quand l’analyse fréquentielle ne suffit pas
Si on a procédé «à la main» pour concevoir le Kéa, c’est parce que l’analyse fréquentielle ne peut favoriser les associations qui permettent une meilleure mémorisation du clavier. Explication.
L’analyse fréquentielle est pertinente pour les caractères les plus utilisés. En revanche, on considère que l’utilisation d’une mnémotechnique est préférable pour les caractères peu utilisés. Car l’automatisation de l’écriture avec les caractères spéciaux va forcément prendre beaucoup plus de temps. En ayant, un moyen de se souvenir on va plus vite dans la recherche.
De plus, même pour les lettres fortement utilisées, on peut combiner la méthode fréquentielle et la méthode mnémotechnique (autant que possible en tout cas).
La logique mnémotechnique utilisée est forcément arbitraire et peut être discutée. Pour Kéa, on a choisi la logique de la phonétique et de l’origine historique.
En effet, phonétiquement:
- l et r sont proches. (En français, on s’en rend pas bien compte car on utilise le r fricatif [ʁ]. Mais pour l’anglais et l’espagnol, c’est évident.)
- c et s ont une fois sur deux le même son.
- d, t et b sont proches. ( le rapprochement du p n’a pas été possible.)
- n et m sont proches
- u et i sont proches dans la prononciation française (le son u s’écrit [y] dans l’API et la lettre y se prononce [i] pour un français)
- i et y sont proches. (i et y se prononcent [i] ou [j] selon le contexte.)
Plus d’information sur la phonétique ici, ici ou encore ici.
En effet, historiquement:
- v a donné u et w
- i a donné j
- C a donné G
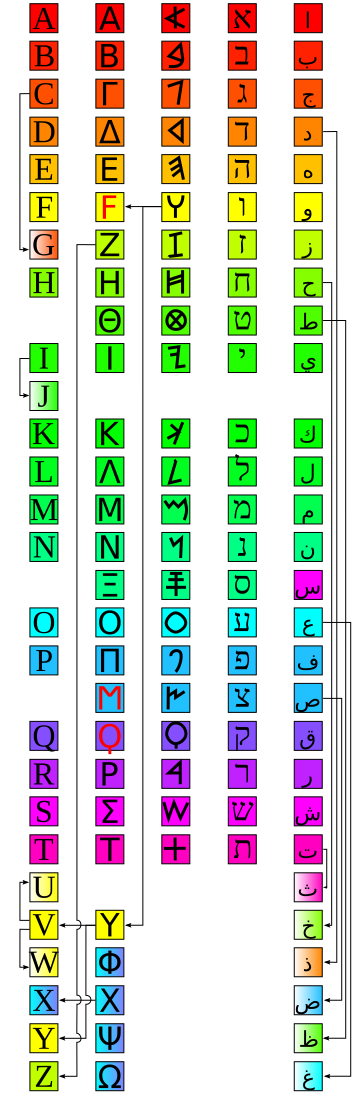
Plus d’information sur la généalogie des alphabets ici et ici.
Le Kéa pour d’autre système d’écriture ?
Pouvoir prendre en compte toutes les langues du monde est un rêve complètement fou étant donné la diversité qu’à produit l’humanité.
{kind=link}
Toutefois, il nous paraît intéressant d’adresser au moins les langues internationales et quelques langues qui ont, disons, notre sympathie.
En cours…